
Dewan learns Kafka - Let’s talk to Kafka
In this week’s blog, I try to make sense of Apache Kafka® ProducerAPI and ConsumerAPI. In an effort to do so, I use a simple Java program to produce some messages to Kafka and consume those messages. After two weeks of theory in the Dewan learns Kafka series, I just NEED to dive in to some code before learning advanced Kafka topics. Yes, that was a “topic” pun… I’ll see myself out.
What do you need to get started?
Last week, I discussed how complex it can get to stand-up a production-ready Kafka cluster by yourself. Since my goal is to actually use Kafka to benefit my application and NOT to learn Kafka administration, I’ll be using a managed Kafka service. You can download Kafka locally or follow these instructions to give Aiven for Apache Kafka® a try. You’ll also need a development environment and some familiarity with the language you choose to talk to Kafka.
I could just ask the magic box that software engineers use whenever they need a production-grade application. But learning doesn’t happen that way. Learning starts at documentation and ends at? That’s a trick question; learning never ends 😉. When writing two simple Kafka producer/consumer programs, I had to check eleventy-zillion documentation pages and kept getting errors. But once I was finally able to get the message to a Kafka topic and read from it, all the effort paid off. Thus, I won’t be copy-pasting my programs here, but rather I’ll share with you my mistakes and successes so that you can take the difficult, yet rewarding learning route. A small heads-up that these programs are merely for learning purposes and might not adhere to best practices.
General guideline
Frameworks are nice in a sense that they abstract away a lot of complexities. When I’m learning though, I don’t want the framework to do all the work. I prefer building the application from its raw form even though it might mean writing more code and not following best practices. To be clear, I don’t mean to rewrite commonly available libraries or client. This only applies to a framework that abstracts away so much that you fail to learn how your application talks to Kafka.
Before you code
- Pick your poison (language of choice)
- Find a popular Kafka client for that language. For example, this for Java, this for NodeJS, or that for Python. The configuration and code snippet I show are for Java but you should be able to use the concept to find something similar for the language you choose.
- Decide whether to use local Kafka installation or a managed Kafka service. For a managed Kafka service, you will have to take care of authentication in your code (much rewarding learning experience).
Producing messages to Kafka
I’m using Java/Maven and added this Kafka Java client and SLF4J framework for logging - both from the Maven repository. I added both dependencies to my pom.xml and you can do similar for whichever client library makes sense for the language you chose.
There are five parts to the actual producer program:
- Add producer properties
- Create the producer instance
- Create a producer record
- Send data
- Close connection
1. Producer properties
If you’re using a local Kafka instance, there are three main properties that you need to set. BOOTSTRAP_SERVERS_CONFIG provides the initial hosts that act as the starting point for a Kafka client to discover the full set of alive servers in the cluster. Kafka converts any data to bytes and the next two configurations tell Kafka what kind of data you’re sending so it can properly do the serialization: KEY_SERIALIZER_CLASS_CONFIG & VALUE_SERIALIZER_CLASS_CONFIG.
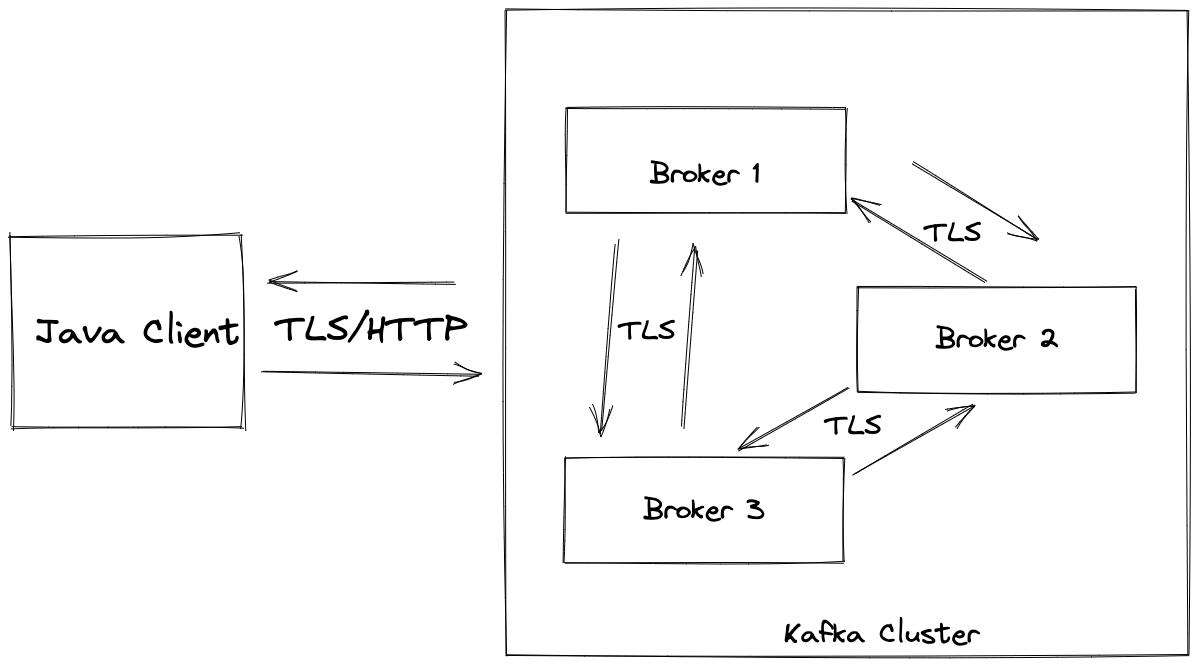
Since I used a managed Kafka service, I had to set SSL-specific features in order to talk to the Kafka cluster. The steps are:
a. Fix the Certificate Authority (CA) b. Create the truststore c. Create the keystore d. Create certificate signing request e. Sign the certificate using CA f. Import the signed certificate and CA into keystore
The CA certificate, Access Certificate, and Access Key will be provided from your managed Kafka service provider.
If the above section seemed super confusing, you’re on the right track! Your first question might be: why do we need authentication and/or encryption? Authentication is required to ensure only certain clients (producer/consumer) can talk to the Kafka cluster. The communication that takes place within the Kafka cluster and between the clients and the brokers are in PLAINTEXT. That is why we need SSL encryption. Secure Sockets Layer (SSL) is the predecessor of Transport Layer Security (TLS), and has been deprecated since June 2015. However, for historical reasons, Kafka (like Java) uses the term/acronym “SSL” instead of “TLS” in configuration and code. I borrowed this information from here and you can read more about encryption and authentication with SSL for Kafka.
2. Create the producer instance
This part was super easy. All you need to do is create an instance of the Kafka producer. Hopefully, the client library you choose, will have good documentation on how to do this. For Java, it was:
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(properties);
3. Create a producer record
There are multiple variations of this constructor. The one I chose requires a topic name (that exists) and a value to be sent.
ProducerRecord<String, String> record =
new ProducerRecord<String, String>("dewans_first_topic", "1002");
4. Send data
This is self-explanatory:
producer.send(record);
5. Close connection
producer.send does NOT actually send the data because it is asynchronous. All it does is enqueue the message on an internal queue which is later (>= queue.buffering.max.ms) served by internal threads and sent to the broker (if a leader is available, else wait some more). To actually send the message, I had to use either flush or close. If you want to keep using the producer and wait for messages to be sent, you would use flush else close. close with timeout value will wait for the messages to be sent and ack received as per the config till time out value and then close the producer. This GitHub issue contains a great discussion on why producers need to either flush or close.
Consuming messages from Kafka
The consumer program is very similar to the producer program. At first, I set the consumer properties, which are almost identical, except that I used KEY_DESERIALIZER_CLASS_CONFIG and VALUE_DESERIALIZER_CLASS_CONFIG because this time the message is being deserialized. Next, I created the consumer instance and subscribed to the topic I created in the producer code.
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Arrays.asList("dewans_first_topic"));
There are few variations of the consumer.subscribe method and the above one takes a Collection as input so you can pass multiple topics to subscribe. The method signature from KafkaConsumer.class:
public void subscribe(Collection<String> topics)
Let’s create a logger to log the messages that we read from the topic.
Logger logger = LoggerFactory.getLogger(ConsumerDemo.class.getName());
Finally, create a ConsumerRecords object that will hold the result of continuous polling. The wacky while(true) loop 🙈 is for testing purpose only and doesn’t contain any elegant programming techniques, for example, exception handling or closing the connection .
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord record : records){
logger.info("Key: " + record.key() + ", Value: " + record.value());
logger.info("Partition: " + record.partition() + " Offset " + record.offset());
}
}
This is indeed an infinite loop. Consumers are usually long-running applications that continuously poll Kafka for more data. The same way that sharks must keep moving or they die, consumers must keep polling Kafka or they will be considered dead and the partitions they are consuming will be handed to another consumer in the group to continue consuming.
Despite mentioning SSL/TLS, I didn’t cover too much on Kafka Security. That’s totally okay as it’s still early days of learning and we’ll get there. Till then, I’ll focus on improving my pun skills and search for the next Kafka item to learn.



