
Dewan learns Kafka - Basics
I am NOT a Kafka expert. The fact is, I’ve just started learning this topic. I believe that the best way to learn something is to learn in public. In this first blog of Dewan learns Kafka series, I share with you what the heck is Kafka, why does it exist, and some basic concepts of Kafka.
What is Kafka?
Kafka is an open-source software that provides a framework for reading, storing, and analyzing massive amounts of streaming data. You can think it of as a distributed commit log that is highly available, scalable, and can act both as a message broker and a publisher-subscriber system.
Why does Kafka exist?
The world produces data - a lot of data. The data goes from some source systems to some target systems. It’s easy to deal with a single data source and a single data target. Imagine the following setup with multiple data sources and targets:
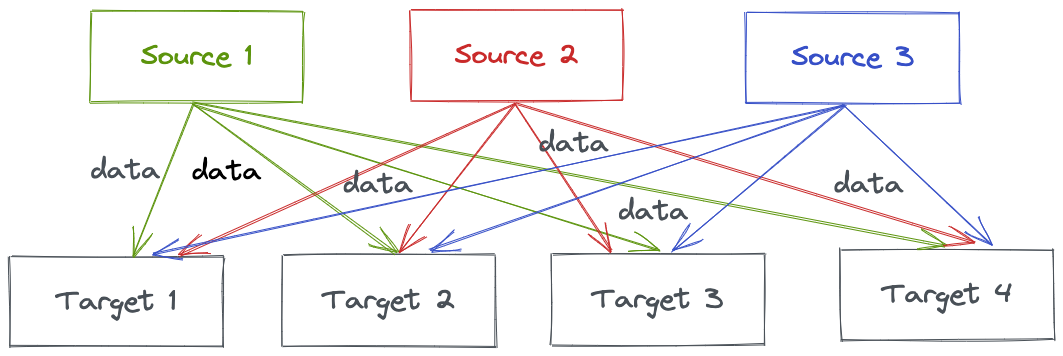
This means that you have to develop multiple integrations to move data across and each integration can have complexities with respect to the protocol, data format, etc. Additionally, every time you add a target, the source systems will experience an increased load.
Kafka lets you decouple the source and target data systems and provides out-of-the-box connectors for the integrations between Kafka and the source/target(s). You don’t need to write code for these integrations.
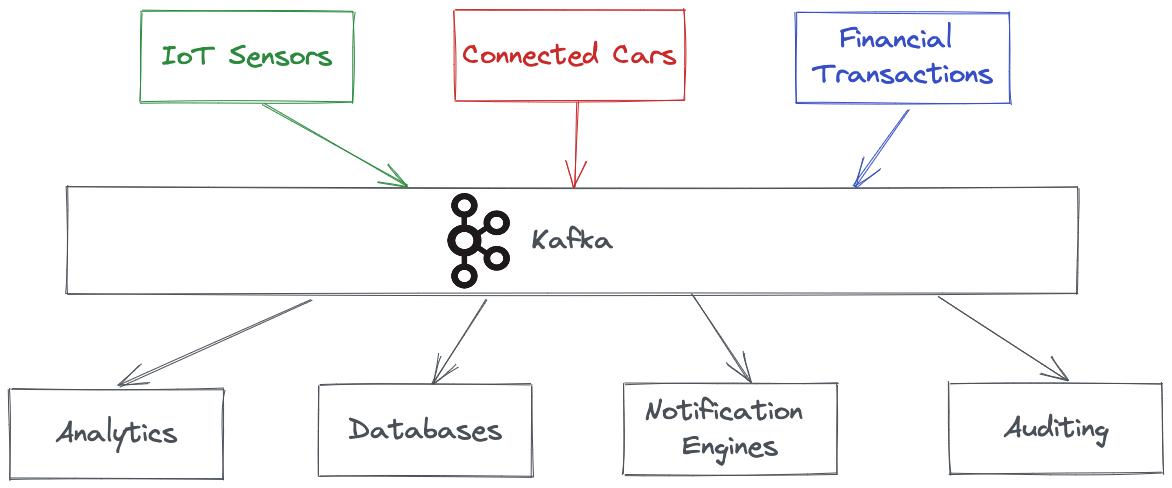
Kafka is highly resilient, can horizontally scale to 100s to brokers exchanging millions of messages per second in real-time. For these reasons, more than 80% of all Fortune 100 companies use Kafka.
Core concepts in Kafka
Events
Traditionally, we have imagined data representing things - an employee, a product, or a thermostat. While this is true in the relational database world, Kafka makes us think of data originating from events. An event is anything that took place - reactions on social media to an IoT sensor sending soil moisture level. When you read or write data to Kafka, you do this in the form of events. Conceptually, an event has a key, value, timestamp, and optional metadata headers.
Topics, partitions, and offsets
Topics are particular streams of data resulting from events. You can think of topics similar to tables in databases. Similar to tables in databases, you can have as many topics as you want. Topics are made of partitions.
A partition is similar to a database partition. Each partition is ordered and each message within a partition gets an incremental id, called offset. When you create a topic, you have to mention the number of partitions (that can be changed later).
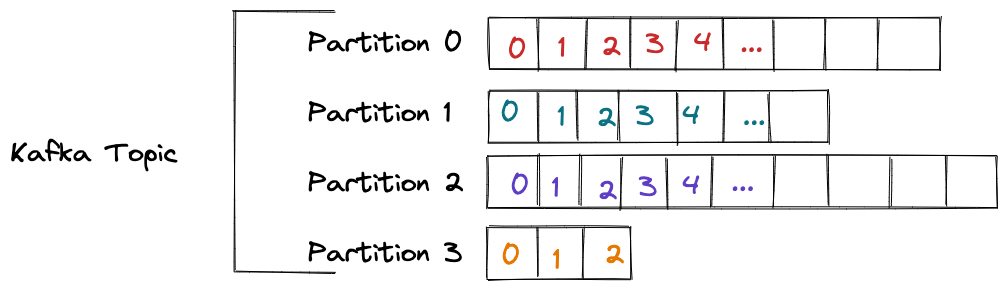
In the above diagram, there are 4 partitions - from partition 0 to partition 3 and they do not contain the same number of messages. You can see that the offset numbers go from 0 all the way up to some large index for the first 3 partitions and the offset number stops at 2 for partition 3 (these are arbitrary numbers). The offset 0 does not mean anything on its own. You have to mention, for example, my_awesome_topic –> partition 3 –> offset 1 for it to make sense. Offsets only have a meaning for a specific partition. Order is guaranteed only within a partition and not across partitions. In the above diagram, we can guarantee that offset 2 in partition 3 has been written after offset 1 within the same partition but we cannot guarantee that offset 2 in partition 3 has been written after offset 1 in partition 2.
Once data is written to a partition, it cannot be changed (immutability feature of Kafka). Data is assigned randomly to a partition unless a key is provided (more on this in later blogs in this series).
Brokers
A Broker is a Kafka server that runs in a Kafka Cluster. From an infrastructure point, Kafka is composed of a network of machines called brokers. These machines can either be physical machines or containers running the Kafka broker process. Each broker hosts some set of Kafka partitions and handles read/write requests to those partitions. Brokers also manage replications of the partitions they host.
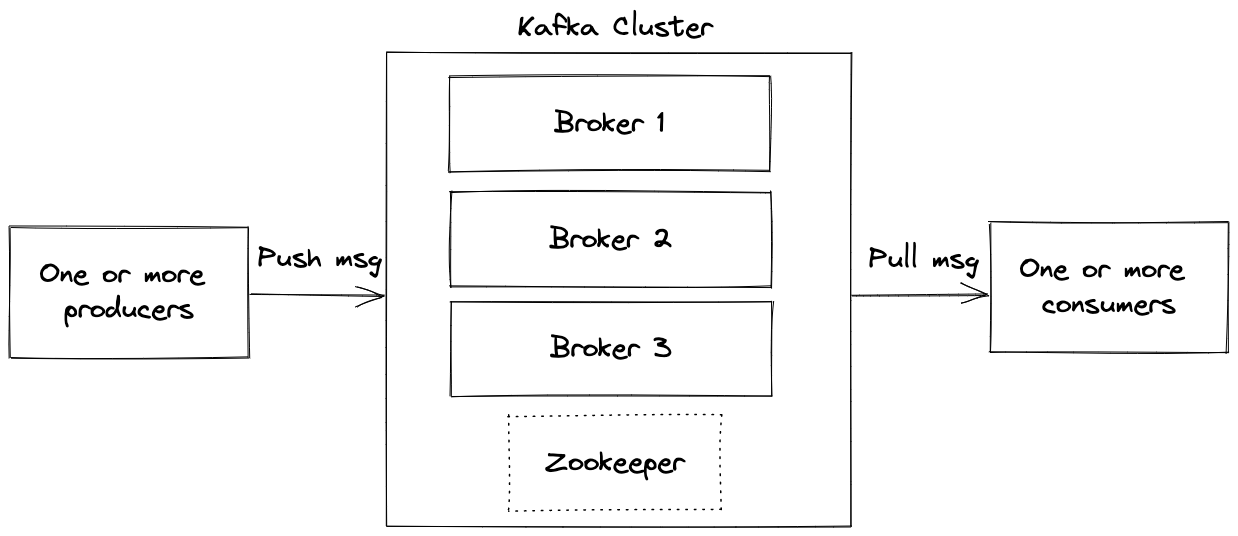
Producers and Consumers
Kafka producers write to Topics and consumers read from Topics. In Kafka, producers and consumers are fully decoupled applications and are agnostic of each other. Producers automatically know which broker and partition to write to. Similarly, consumers know which broker to read from. In case of Broker failures, producers and consumers will automatically recover. Data is read in order within each partition by the consumers.
Consumers read data in consumer groups. A consumer group can subscribe to one or more topics. Each consumer group has at least one consumer. The messages in the partition are not deleted as soon as the consumer reads the data. Hence, these are still available for other consumer groups to consume. Every time a client reads data at a given offset, its offset is incremented and the consumer will read data at the next offset.
Zookeeper
You can compare Zookeeper to a distributed filesystem, but for metadata. You can store any configuration that you want in Zookeeper. If you are writing an application/service that should work on a distributed system you could use Zookeeper to have a centralized configuration. With respect to Kafka, Zookeeper manages the brokers and helps in performing leader election for partitions. Currently, Zookeeper is a prerequisite for Kafka (although it’s in the process of being removed ). For managed Kafka services, you might not see the Zookeeper but know that it exists.
I didn’t capture every single Kafka concept in this first blog. As I learn, I’ll continue adding more blogs to this series. If you’re learning Kafka, let’s learn together and keep an eye out for the next blog. Please let me know if you have any feedback on this blog.



