
ripgrep - an extremely fast grep alternative
If you’ve used grep to search for text or patterns in files, you’ll love ripgrep - a command-line utility tool written in Rust. By default, ripgrep will respect gitignore rules and automatically skip hidden files/directories and binary files. ripgrep is grep on steroids. It’s super fast for searching patterns within single files and huge directories of files. In this blog, I’ll help you get started with using ripgrep and hope it’ll help you become more productive on the command-line.
Installation and sample data
The first thing you’ll do is install ripgrep. It has first class support on Windows, macOS and Linux. Choose one of many installation options or you can build it from source. Fortunately, the binary is not called ripgrep; it’s rg.
I have generated some sample server data which I’ll use to test drive ripgrep. Feel free to download this public gist to play along. Each mock-server-dataX.json file has 1000 random server data and mock-server.conf file has a sample PostgreSQL configuration data.
Searching within a single file
rg port mock-server-data1.json
We’re telling ripgrep to search for the pattern “port” within a single file. You should see a 1000-line output since every object in that JSON array contains the “port” field.
Let’s try something specific:
rg 9778b33b-2c49-4340-a9b5-320339052ec0 mock-server-data1.json
When searching for a particular UUID within the file mock-server-data1.json, you should see only one row as a result. This is helpful. But does this UUID exist in other files?
Recursive search
Since ripgrep searches recursively by default, you don’t have to do anything special other than omitting the individual file name.
rg 9778b33b-2c49-4340-a9b5-320339052ec0
Since you didn’t specify a file name, ripgrep will search the current directory and sub-directories for files that contain the UUID 9778b33b-2c49-4340-a9b5-320339052ec0.
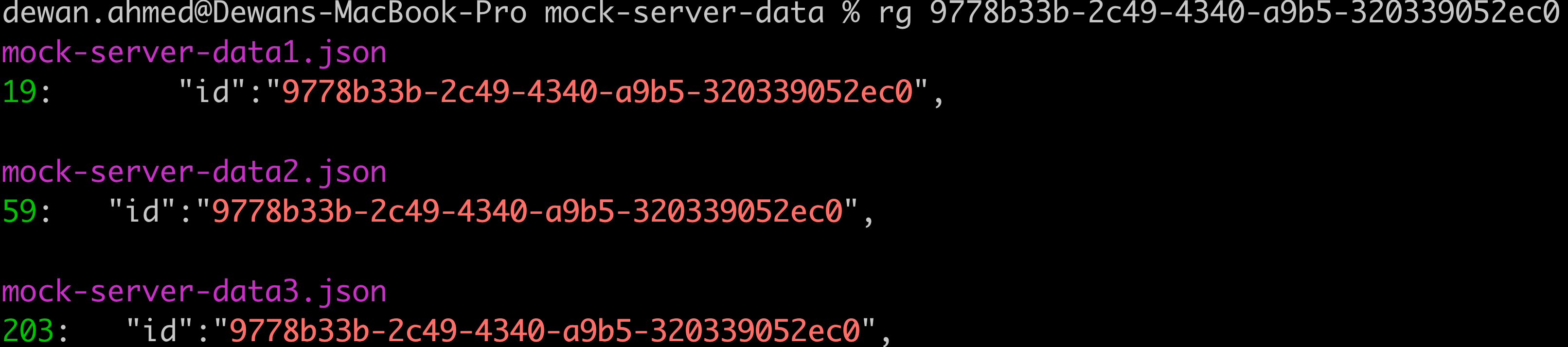
Not only ripgrep color-codes the search result, it also tells us the line number on the files where the pattern appears. Let’s validate this finding:
vim +203 mock-server-data3.json
The above command opens mock-server-data3.json on line 203. Did you know this vim shortcut? :set nu will confirm that the UUID 9778b33b-2c49-4340-a9b5-320339052ec0 is shown on this line.
Pattern search
The test data has some errors. Some of the fields contain emails although there isn’t a field for email. Let’s use regex to find these anomalies:
rg -e "[a-zA-Z0-9_]+@[a-z]+.[a-z]+" .
The -e flag is the regex option and the above is a poorly built email regex. The output is as follows:
./mock-server-data2.json
104: "password": "test@test.com"
./mock-server-data3.json
152: "password": "test@test.com"
288: "password": "info@info.ca"
./mock-server-data1.json
48: "password":"test@test.com"
112: "password":"test@test.com"
We can see that some of the password fields incorrectly contain emails. Theoretically, it’s possible that someone might be using the email as the password. But considering that these are randomly generated server passwords, we’ll treat these as errors.
gitignore and hidden files
ripgrep won’t show these file types .rgignore, .gitignore, and .ignore
in search results. Although you can disable all ignore-related fltering with the --no-ignore flag. ripgrep will also respect repository specific rules found in $GIT_DIR/info/exclude, as well as any global ignore rules in your core.excludesFile.
Let’s test this out:
rg tcp_keepalives_count
The output:
mock-server.conf
84:#tcp_keepalives_count = 0 # TCP_KEEPCNT;
Let’s add mock-server.conf file to .gitignore, .ignore, or .rignore.
Now if you re-run the previous search, there wouldn’t be any output since ripgrep is filtering the mock-server.conf file out of the search.
Performance
To get the maximum performance, ripgrep runs in a multi-threaded way which means that the result shown will not be in the same order for the same search running multiple times. The way ripgrep sorts the output is based on whichever file gets searched first. You can pass the --sort flag to sort the output which will come at the cost of some performance.
The line number and color cording are not the main selling point (it’s open-source so no one’s selling you anything ![]() ) for
) for ripgrep. Its main feature is being extremely fast and the author Andrew Gallant wrote a detailed blog on ripgrep benchmark.
I was inspired by Brodie Robertson and Jay LaCroix to use ripgrep so thank you both. If you’ve given ripgrep a try, please let me know how your experience was.



